Scientists propose a new tuning scheme to enhance the performance of multiple mo
2024-04-04
The advent of large language models represented by ChatGPT marks a new milestone in the field of AI.
At the same time, the development of multimodal large models capable of processing text, images, audio, and video data has added "eyes" and "ears" to large language models, making them comprehensive intelligent entities with diverse perceptual abilities and strong knowledge understanding capabilities.
Due to their excellent generalization and transferability, which can enhance the multimodal understanding and generation capabilities of large models, multimodal large models have now become a new track in the development of AI.
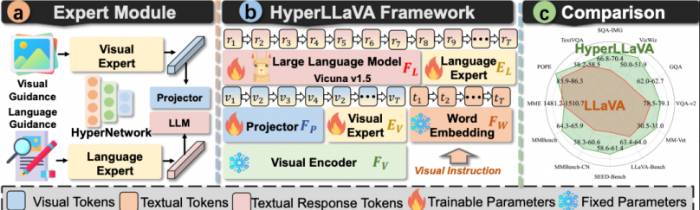
It is understood that the current paradigm of multimodal large models, such as LLaVA, usually follows a two-stage training model.
The first stage is the alignment of vision and language. By using a static projector to match visual features with the word embedding space of the language model, the large language model is able to understand visual content.The second phase, multimodal instruction fine-tuning. By fine-tuning the large language model with the constructed visual-language instruction set, it can better respond to a variety of user requests involving visual content.
Advertisement
Although these two phases are crucial, there is still relatively little research related to the projector structure and large language model adjustment strategies.
Existing methods still adopt the static parameter multimodal large model architecture, and this parameter sharing mode between different tasks has limitations when dealing with a variety of multimodal tasks.
To break through this limitation, the research team from Zhejiang University, Shanghai University of Science and Technology, Chongqing University, Alibaba Group, and Harbin Institute of Technology proposed HyperLLaVA.
They use hyperparameter networks HyperNetworks and adapters to build dynamic expert modules, which can adaptively generate dynamic parameters based on sensory input perception, integrating the static multimodal model architecture with dynamically adjusted expert modules, thereby effectively enhancing the generalization ability of multimodal large models in different downstream multimodal tasks.Specifically:
Firstly, in the visual and language alignment phase, the projector is decomposed into a static layer and a dynamic layer.
In this, the parameters of the static layer remain unchanged, while the parameters of the dynamic layer are dynamically generated according to the input visual features. This will assist the static projector in completing adaptive feature modeling based on input perception, and then flexibly convert visual features into text tokens to achieve fine-grained visual-language semantic space alignment.
Secondly, in the multimodal instruction fine-tuning phase, a language expert is equipped for the large language model to model the dynamic parameters of the large language model block.
That is to say, the intermediate output of the large language model is regarded as implicit language prior knowledge, guiding the language expert to generate unique parameters for each input.Language experts can leverage the similarities between cross-dataset samples to avoid potential interference between samples within the dataset, thereby enhancing the flexibility and generalizability of multimodal large models in handling downstream multimodal tasks.
In addition, the language expert can also serve as an efficient parameter fine-tuning method for multimodal large models, achieving performance close to that of full fine-tuning.
"We hope that the proposed HyperLLaVA can provide a more stable and flexible framework for multimodal large model architectures, pushing the boundaries of multimodal multi-task processing capabilities," said Zhang Wenqiao, a researcher of the "Hundred Talents Program" at Zhejiang University who participated in this study.
Currently, the specific applications of HyperLLaVA can be divided into the following two aspects.
Firstly, in the general domain, HyperLLaVA can help large models adapt to the subtle differences between different multimodal inputs through the collaboration of visual and language experts, and enhance the perception, cognition, and reasoning capabilities of existing general multimodal large models as a plug-and-play module.Further enhance the performance of multimodal large models on general tasks such as mathematical reasoning, copywriting creation, and natural language translation.
Secondly, in vertical fields, the visual and language experts in HyperLLaVA can accept additional professional visual knowledge and textual knowledge in specific fields, making up for the "lack of professionalism" in general large models. This achieves mutual guidance and promotion between data-driven and knowledge-driven approaches, thereby enhancing the professionalism and credibility of multimodal large models when fine-tuning instructions in vertical fields.
For example, in the financial field, it can answer questions raised by investors and provide corresponding advice to assist them in making good investment decisions.
In the legal field, it can help users and lawyers with legal consultations and legal affairs handling; in the medical field, it can assist doctors with diagnosis and treatment, alleviating their work pressure.
Recently, the relevant paper was published on the preprint platform arXiv with the title "HyperLLaVA: Dynamic Visual and Language Expert Tuning for Multimodal Large Language Models" [1].Zhejiang University's Zhang Wenqiao, Shanghai University of Science and Technology's Lin Tianwei, and Chongqing University's Liu Jiang are the first authors, while Professor Zhuang Yueting from Zhejiang University and Li Juncheng, along with Jiang Hao from Alibaba Group, serve as the corresponding authors.
According to Zhang Wenqiao, the research began with a comprehensive assessment of current multimodal large models.
"Although an increasing number of studies tend to adopt the Mixture of Experts (MoE) model, which enhances the overall performance of the model by cultivating specialized experts for different domains and drawing on the strategies of ensemble learning," he said.
However, effectively matching specific corpora with the corresponding experts during the training process remains a thorny issue.
Moreover, with the advancement of large model technology, a single static model has certain limitations when dealing with multimodal and multi-task scenarios, and even the Mixture of Experts model faces issues of knowledge conflict and forgetting among specific experts.Therefore, this fixed static parameter architecture may limit the performance of different downstream tasks.
It is precisely the limitations of the existing static multimodal large model architecture that have inspired the research team's interest in exploring dynamic strategies, thereby laying the foundation for further research.
Next, during the conceptualization phase, the team closely monitored the latest developments in the field and possible solutions, and conducted in-depth research on work related to multiple tasks and domains.
"By combining the latest research findings and literature for extensive thinking and discussion, we proposed the preliminary concept of HyperLLaVA, a model that can dynamically generate visual and language experts using a hyperparameter network, and then adaptively adjust parameters," said Zhang Wenqiao.
After clarifying the research direction and methods, the researchers began to work on the actual development and experiments of HyperLLaVA.They conducted a rigorous assessment of the preliminary prototype model, and then carried out continuous optimization and iteration based on performance indicators and feedback.
It is understood that this iterative process is very critical for promoting the ultimate development of model performance and verifying the feasibility of its practical application.
Subsequently, they put the improved model through extensive experimental verification in multiple benchmark tests and real scenarios, aiming to evaluate its performance and compare it with existing models.
In addition, they also carried out a series of ablation experiments, and through comparative analysis, deeply explored the working principles of the model, and detailed the research process, methodology, experimental results, and interpretive analysis.
Zhang Wenqiao said that during the process of the research, when the research team decided to use a hyperparameter network to enhance the performance of vision and language experts, they first tried to use a large network structure, but found that this would lead to uncontrollable training of multimodal large models, and thus could not achieve the expected results.According to our analysis, this is due to the scale of the generated network parameters being too large, and the training data cannot fit. Zhang Wenqiao said.
So, in the subsequent many tests, they spent a lot of time and resources for debugging, but they could not achieve good results.
"We even gave up the proposed plan for a while." Zhang Wenqiao frankly said.
However, in a chance test, the team found that the model showed unexpected performance advantages and training stability in smaller dimensions.
This made them decide to combine the up-sampling and down-sampling network structure, to further control the scale of the generated network parameters, and finally effectively enhance the controllability and generalization of network training.In addition to this, researchers have also observed that hyperparameter networks, as a dynamic adjustment mechanism, bear some resemblance to meta-learning to a certain extent.
This can enhance the model's ability to apply across different domains and enable the model to utilize this cross-domain potential for self-adjustment during the training process.
Building on this research, the research team will continue to pay attention to the latest developments in large model technology, exploring how to further improve HyperLLaVA and to develop new powerful paradigms in the field of multimodal large models.
For instance, at the model architecture level, by combining the training of general visual/language experts and specific visual/language experts with the Mixture of Experts (MoE) technology, the collaboration and integration of the two can further enhance the generalizability of multimodal large models in downstream tasks.
At the model scale level, by collecting larger-scale multimodal training instructions and training the model on larger base language models (such as 34B, 130B), a more powerful general multimodal large model can be constructed.In terms of application demonstration, preliminary implementation has been achieved in the medical field, constructing multimodal instruction data based on medical imaging, medical knowledge graphs, medical consultation databases, etc., to achieve fine-grained medical image parsing, basic consultation, and the generation of diagnostic reports, among other functions.
Leave a comment
Join the family
Leave your email and subscribe to our latest articles